











「数据中台」企业数据中台应用层介绍,数据应用层严格来说不属于数据中心的范畴,但数据中心的使命是赋予业务能力,大多数企业在建设数据中心的同时计划数据应用。数据应用可以根据数据的使用场景分为以下几个使用领域。
1)分析和决策的应用。
分析和决策应用主要面向企业领导、运营人员等作用,基于企业业务背景和数据分析诉求,对客户提供新的、老客户运营、销售能力评价等分析场景,通过主题域模型、标签模型和算法模型,为企业提供视觉分析主题。
用户可以在分析和决策应用中快速获得企业现状和问题,同时深入分析数据、联动分析等企业问题及其原因,帮助企业管理和决策,实现正确的管理和智能决策。
在分析主题设计过程中,首先要根据业务分析场景,采用不同的分析方法进行数据分析的前期计划,构建明确的数据分析框架,例如在用户行为分析、市场营销活动等场景下,采用5W2H分析法和4P市场营销理论
数据分析框架构建完成后,结合用户的分析目的,采用不同的分析思路和呈现方式,包括趋势分析、多维分解、漏斗分析、A/B测试、比较分析和交叉分析等。
2)标签的应用。
标签是为了挖掘实体对象(顾客、商品等)的特征,将数据转化为真正对业务有价值的产品,对外提供标签数据服务,应用于顾客的选择、正确的市场营销和个性化的推荐等场景,实现资产的变化,扩大资产价值。
标签系统的设计立足于标签的使用场景,不同的使用场景对标签的需求不同。例如,在客户个性化推荐场景下,需要客户性别、最近关注商品类型、消费能力和消费习惯等标签。
因此,在标签系统设计之前,有必要根据业务需求分析标签的使用场景,然后详细设计标签系统和规则。在标签的使用过程中,可以利用A/B测试等数据分析方式,不断分析标签的使用效果,优化标签系统和规则。
3)智能应用。
智能应用是数字智能化的典型外在表现。例如,在市场营销领域,不仅可以实现千人千面的用户个性化推荐,还可以通过智能营销工具进行高精度的用户接触,推进首次购买转换、二次购买促进、流失保留等。
在供应链领域,用户数据、销售数据、用户数据、销售数据、采购数据等优化库存,实现自动补充、自动定价。除了传统的统计分析、机械学习外,还可以融入深入的学习,通过图纸搜索图纸,实现与商业街的联系,实现实现立即购买的脸部识别,融入用于房地产行业的事件场所控制的自然语言处理,实现智能呼叫问答机器人等。
总而言之,以上是数据中台的核心内容。需要指出的是,在工具平台层,企业不需要完全自主建设,可以考虑采用带来主义,从中台建设厂商购买成熟的产品,数据资产层和数据应用层需要企业数据中台组织密切关注。
随着大数据和人工智能技术的反复和商业大数据工具产品的发售,数据中心的结构设计不需要从零开始,可以购买一站式的研究开发平台产品,也可以根据开源产品进行组装。企业可以根据自己的情况进行权衡考虑,但无论采用什么样的方案,数据结构设计都以满足当前数据处理的全场景为基准。
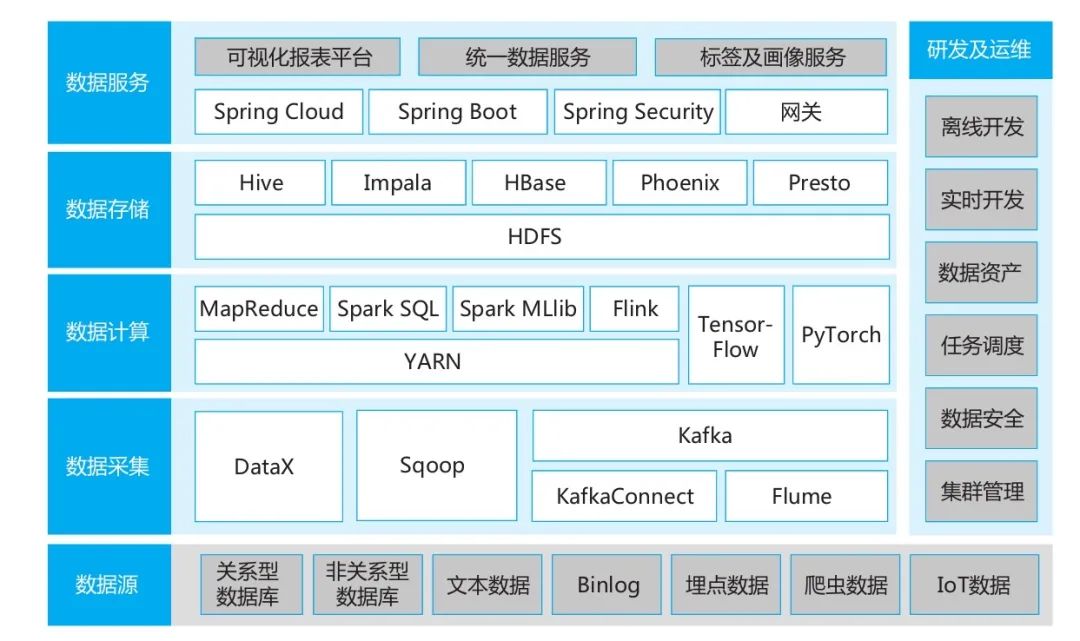
以开源技术为例,数据中心的技术结构如图所示,一般包括数据收集、数据计算、数据存储和数据服务在内的开发、运输维护和公共服务方面包括离线开发、实时开发、数据资产、任务调度、数据安全、集体管理。
数据中的桌子包括什么?详细了解结构的设计和构成。
1.数据收集层。
根据数据的实时性,数据采集分为线下采集和实时采集。离线采集使用DataX和Sqoop,实时采集KafkaConnect、Flume和Kafka。
线下数据采集中,建议使用DataX与Sqoop相结合。DataX适用于数据量小、采用非关系数据库的场景,配置方式简单。Sqoop适用于数据量大、采用相关型数据库的场景。
在实时数据收集中,MySQL的binlog、Oracle的OGG等数据库的变更数据,使用KafkaConnect进行数据的实时收集。对于其他数据,首先将数据实时写成文件,然后使用Flume实时收集文件内容。将实时采集的数据推送到Kafka,Flink进行数据处理。
2.数据计算层。
数据计算采用YARN作为各种计算框架部署的执行调度平台,计算框架包括Mapreduce、Spark和SparkSQL、Flink、SparkMLlib等。
MapReduce是最初开源的大数据计算框架,现在性能比较差,但资源占有比较小,特别是存储器。因此,一些数据量过大,其他计算框架由于硬件资源的限制(主要是存储器的限制)而无法执行的场景,可以将MapReduce作为替代框架。
Spark和SparkSQL是批处理方面具有优异性能的成熟技术方案,适用于大部分离线处理场景。特别是在线下数据建模方面,建议使用SparkSQL进行数据处理,这样既能保证好用又能保证处理的性能。Flink是实时数据处理的优先事项,在处理时效性、性能和易用性方面具有很大优势。
机械学习一般以Spark家族的SparkMLlib为技术基础。SparkMLlib内置了许多常规算法包,如随机森林、逻辑回归、决策树等,可以满足大部分数据智能应用场景。
同时,数据中心不断进化,逐渐融入AI能力。人脸识别、图搜索图、智能呼叫等能力的实现需要AI平台。目前成熟的AI平台有TensorFlow和PyTorch。为了实现对象的检测和识别,可以使用SSD、YOLO、ResNet等深入的学习模型,在脸部检测和识别中主要使用MTCNN、RetinaNet和ResNet,脸部检索可以使用脸部检索开源的脸部检索
3.数据存储层。
数据存储层的所有存储引擎都基于Hadoop的HDFS分布式存储,从而实现数据多冗馀和物理层多磁盘的I/O性能。HDFS分别构建Hive、HBase作为存储数据库,在这两个数据库的基础上构建Impala、Phoenix、Presto引擎。
Hive是大数据广泛使用的线下数据存储平台,用于存储数据中台的全量数据,在建模阶段可以使用HiveSQL、SparkSQL进行数据处理和建模。
HBase是主流的大数据NoSQL,适合数据的快速实时读写。在进行实时数据处理的时候,可以将数据实时的保存到HBase中,并且可以从HBase中实时的阅读数据,从而满足数据的时效性。
Impala可以对Hive、HBase等大数据库进行准时的数据分析,以满足分析结果速度有一定要求的场景。
Phoenix是构建在HBase上的SQL层,不是HBase客户端API,而是用标准的JDBCAPI制作表格、插入数据、查询HBase数据。
Presto是开源的分布式SQL查询引擎,适用于交互式分析查询。Presto支持Hive、HBase、MySQL等多种关系类型和大数据库查询,支持join表格。对于自助分析统一数据服务的场景,可以通过Presto统一访问具体存储的数据库,实现语法统一和数据源统一。
4.数据服务层。
「数据中台」企业数据中台应用层介绍数据服务层所采用的技术与业务应用类似,主要是基于开源SpringCloud、SpringBoot等构建,使用统一的服务网关。








@Copyrights 2016-2026 杭州玳数科技有限公司浙ICP备15044486号-1浙公网安备33011002011932号

