











什么是数据仓库?为什么要建设数据仓库?什么是数仓,为什么建数仓,怎么建数仓(我是谁,从哪里来,我去哪里)
 Inmon将数据仓库理解为:面对企业经营管理和战略决策的主题,集成的,与时间相关的,无法改变的数据信息集合。资料仓库总体目标:资料资产,战略决策资料。
Inmon将数据仓库理解为:面对企业经营管理和战略决策的主题,集成的,与时间相关的,无法改变的数据信息集合。资料仓库总体目标:资料资产,战略决策资料。
什么是数据仓库?为什么要建设数据仓库?
etl过程:打开你的任督二脉(离线+实时),让数据信息在整个阶段流通。
资料资料分层:一整套(低耦合,高内聚)的层次,非常重要。总是不改变业务,数据信息等等,数仓像又投胎了。
资料整合:在多业务场景下,突破资料资料壁垒,避免资料资料歧义,统一资料服务。
标准化:保持良好的系统化、标准化设计,会产生易于维护和高度扩展。
监督和辅助:质量监督,生产调度监督,元数据管理,网络信息安全监督。
方向服务:外部api服务/自助查询平台/OLAP分析服务平台。
即时数仓:有机会重写。
合作。
与后端工程师合作:依靠上下游,必须有一个良好的渠道来保证资源共享和联动响应。
和分析/业务握手:下游服务,需求方有很多以是分析,也可以是运营/boss,首先要了解他们,让他们了解你。
迭代仓库:只要业务在发展,仓库就必须不断更新;响应业务变化,丰富数据模型。
个人角色。
责任:做好数据整合,保持数据准确性,建立数字仓库权威。
工作安排:简单的事情复杂,复杂的事情简单(简单的事情系统,复杂的事情系统,标准化)
沟通:鲁迅说,双赢才是真理。
掌握技能:优化查询、高效存储和模型理论。
ETL
由于数据信息应用场景的不同,数据存储方案也有很大差异。mysql/Mssql/oracle和hive/hbase/MongDB、excel/csv/txt/api等。
要求。
业务场景覆盖。
业务数据信息往往涉及多种数据源,数据存储往往有多种选择。文本数据信息、日志数据信息、RMDB、Nosql等。要求etl工具覆盖这些业务场景。
性能。
商业特征在数据信息方面,往往有波峰谷。能否保持高峰期。例如常见的双11,618等消费节日。并且随着业务步伐的扩大,能否面对后期数据量的增长。
可扩展性。
数据信息etl工作从源端进行,当数据结构发生变化,数据删除,数据源发生变化,数据类型发生变化时,必须更好地扩展,保持与数据质量监督,元数据管理的互动。
工具。
datax/sqoop/kettle/informatica等。
应该满足。
连续的数据信息不应该从某个时间点删除;现有数据信息不应该更改。
ETL一般是最初的部分,上午以后的时间点。a:避免集中对jdbc的大规模同步,影响业务(部分从库可能提供查询服务)、b:明确生产计划的时间段,必须尽量在某个时间段内完成(不仅仅是生产计划,还要实现任务流的串行,为后期的大作业空间,占有等待的系统资源)。
应记录数据同步过程中涉及的元数据。包括:操作细节、开始/结束时间、资源消耗、过程状态等。
面临的问题。
如果源数据结构发生变化(例如在mysql的表中添加字段),则可以实现低成本的扩展,从而实现业务零感知。应考虑在设计初期。可以通过元数据监控,自动实现动态数据信息扩展。
数据加载错误(字段类型、数据信息缺失,多表同步,档案载入,空值异常)
分层。
层次化的出发点
我想用我周围的房子来描述分层设计。从直观的角度来看,分层是一种层次/功能关系。数字仓库反映为:ods/dw/dm。每层都做自己的事,比如家里的厨房、卫生间、客厅。你不想还在睡觉,被别人早上的第一次清流吵醒。
对于数字仓库来说,第一层是解决功能界限,厨房只做烹饪和烹饪;第二,解决问题,隔离和快速定位到卧室;如有烟味,请打开排气扇。
层次设计
设计原则。
层次清晰。
功能清晰。
内部没有依赖。
常见的分层结构。
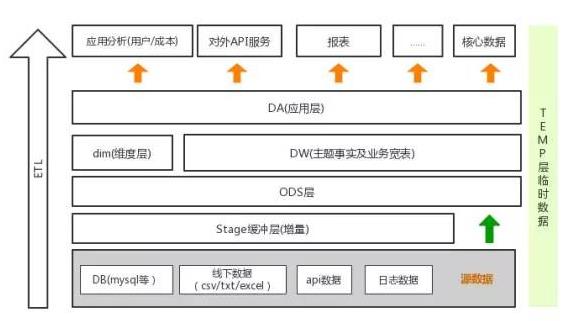
从0建立离线数据仓库。
数字仓库-分层。
Stage缓冲层。
交易数据信息,每日增量方式数据同步。在数据同步过程中,一定要注意边界问题,避免脏数据。对非交易数据信息,一般通过快照/全量更新。数据查询不开放。
ODS层。
在一般情况下,我们认为这一层的数据信息与在线一致。在实际处理过程中,为了处理时间维度上的数据信息变化,会记录数据信息的变化轨迹(缓慢变化维度)。对这部分数据信息,应有选择地实施,避免业务处理过程复杂,问题出现后难以追溯。
DIM/DW层(模型层)
在ods层的基础上,设计一个宽表层/模型层,通过维度建模实现维度数据信息与事实数据信息的分离(星形模型)。此外,丰富的宽度表可以弥补星形模型的未覆盖性。以此来满足业务场景的需求。
DA层(应用层)
面对不同的应用,聚合数据信息层。使用DIM/DW层是模型层的检测维度。
面临的问题。
资料资料分层实际解决的是,不同层次之间的界限,做到井水不犯河水(高内聚低耦合)。在实际工作中,应结合业务处理流程,对所涉数据处理流程,确定相应的功能界限,并加以遵守和监督。尽管如此,仍然存在一些问题。
历史数据再现:依赖的数据信息错误,如DIM依赖的ods层数据信息有问题。问题数据信息可能是当天,也可能是一段时间。DIM历史数据如何更新为正确的数据信息?
性能问题:对于日志数据信息和大型事务数据信息,更新数据信息时性能较差。
层次化重建:在初始层次化设计中,将某些流程冗余到另一个层次。早期应该如何处理,后期应该如何低成本剥离。
模型构建。
数据仓库是一个工程建设,而不是独立的模块开发。从全局来看,数据仓库的建设要考虑与源数据信息的互动、质量监管、如何为外界提供数据服务等。在这些工作中,模型的建设可以说是灵魂的存在。满足集成、历史、主题要求,涵盖业务多场景需求,提供决策性企业数据。
水无定势,士兵无常。不同的行业有不同的需求,不同的模型解决不同的问题。
为何建立模型?
全面梳理业务,完善业务流程。在业务模型建设阶段,可以帮助我们的企业或监管机构全面梳理我们单位的业务。通过业务模型的建立,我们应该能够充分了解该单位的业务结构图和整体业务的运行情况,按照特定的规律对业务进行分类和程序化,同时帮助我们进一步改进业务流程,提高业务效率,指导我们业务部门的生产。
建立全方位的数据信息视角,消除信息孤岛和数据信息的差异。通过建立数据仓库模型,可以为企业提供整体的数据信息视角,不再是各部门只关注自己的数据信息,而是通过建立模型,勾勒出部门之间的内在联系,帮助消除各部门之间的信息孤岛问题。更重要的是,通过建立数据模型,可以保证整个企业的数据信息一致性,有效解决各部门之间的数据信息差异。
解决业务变化和数据仓库灵活性。通过构建数据模型,可以很好地分离底层技术的实现和上层业务的展示。当上层业务发生变化时,通过数据模型,底层技术可以很容易地完成业务变化,从而实现整个数据仓库系统的灵活性。
什么是数据仓库?为什么要建设数据仓库?帮助建立数据仓库系统本身。通过建立数据仓库模型,开发人员和业务人员可以轻松实现系统建设范围的定义和长期总体目标的规划,从而使整个项目组明确当前任务,加快整个系统建设。








@Copyrights 2016-2026 杭州玳数科技有限公司浙ICP备15044486号-1浙公网安备33011002011932号

