











大数据挖掘(Datamining)又译为材料探勘、数据信息开采。它是数据库查询专业知识发觉(英文:Knowledge-DiscoveryinDatabases,通称:KDD)中的一个流程。大数据挖掘一般就是指从很多的数据信息中根据优化算法检索掩藏于在其中信息内容的全过程。大数据挖掘一般 与电子信息科学相关,并根据统计分析、线上剖析解决、情报检索、深度学习、数据管理系统(借助以往的工作经验规律)和系统识别等众多方式 来保持所述总体目标。
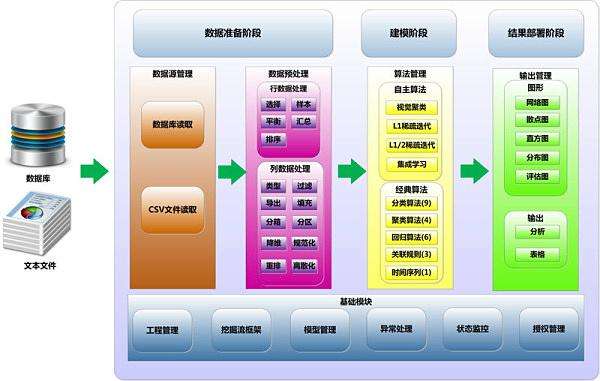
大部分数据信息是是非非结构型的,因而必须一个全过程和方式 从数据信息中获取有效的信息内容,并将其变换为可了解的和能用的方式。大数据挖掘或“数据库查询中的专业知识发觉”是根据人工智能技术、深度学习、统计分析和数据库管理发觉互联网大数据集中化的方式的全过程。
大数据挖掘中一般 涉及四种每日任务:归类:将了解的构造归纳为新数据的每日任务;聚类算法:在数据信息中以某类方法搜索组和构造的每日任务,而不用在数据信息中应用已留意的构造;关联规则学习培训:搜索自变量中间的关联;重归:致力于寻找一个涵数,用最少的不正确来仿真模拟数据信息。
经典算法编写
1.C4.5:是深度学习优化算法中的一种归类决策树算法,其关键优化算法是ID3优化算法。
2.K-means优化算法:是一种聚类算法。
3.SVM:一种监管式学习方法,普遍应用于统计分析归类及其回归分析中
4.Apriori:是一种最有影响的发掘布尔运算关联规则经常项集的优化算法。
5.EM:较大 期待值法。
6.pagerank:是google优化算法的关键內容。
7.Adaboost:是一种迭代算法,其核心内容是对于同一个训练集训炼不一样的分类器随后把弱分类器集合起来,组成一个更强的最后分类器。
8.KNN:是一个理论上较为完善的的方式 ,也是非常简单的深度学习方式 之一。
9.NaiveBayes:在诸多分类方法中,运用最普遍的有决策树模型和朴素贝叶斯(NaiveBayes)。
10.Cart:归类与回归树,在归类树下边有两个重要的观念,第一个是有关递归地区划自变量室内空间的念头,第二个是用认证数据信息开展减枝。
大数据挖掘专用工具
1.RapidMinerRapidMiner,是一个用以深度学习和大数据挖掘试验的自然环境,用以科学研究和具体的大数据挖掘每日任务。不容置疑,它是技术领先的大数据挖掘开源网站。该专用工具以Java计算机语言撰写,根据根据模版的架构出示高級剖析。它促使试验能够 由很多的可随意嵌套循环的操作符构成,这种操作符在XML文档中是详尽的,而且是由迅速的Miner的人机交互界面进行的。最好是的是客户不用撰写编码。它早已有很多模版和别的专用工具,我们一起能够 轻轻松松地分析数据。
2.IBMSPSSModelerIBMSPSSModeler专用工具操作台,最合适解决文本分析等工程项目,其数据可视化页面十分有使用价值。它容许您不在程序编写的状况下转化成各种各样大数据挖掘优化算法。它还可以用以异常检测、贝叶斯网络、CARMA、Cox重归及其应用多层感知器开展反向传播学习培训的基础神经元网络。
3.OracleDataMiningOracle,做为“高級剖析数据库查询”选择项的一部分,Oracle大数据挖掘作用容许其客户发觉判断力,开展预测分析并运用其Oracle数据信息。您能够 搭建实体模型来发觉顾客个人行为目标客户和开发设计概述文档。OracleDataMinerGUI使大数据分析师、业务流程投资分析师和大数据工程师可以应用非常雅致的拖拽解决方法解决数据库查询内的数据信息。它可以为全部公司的自动化技术、生产调度和布署建立SQL和PL/SQL脚本制作。
4.TeradataTeradata了解到,虽然互联网大数据是令人钦佩的,但假如您事实上并不了解怎样剖析和应用它,那麼它是毫无用处的。想像一下,有数千万的数据信息点沒有查寻的专业技能。这就是Teradata所出示的。他们出示数据库管理,互联网大数据和剖析及其网络营销程序运行层面的端到端解决方法和服务项目。Teradata还出示一系列的服务项目,包含执行,业务流程资询,学习培训和适用。
5.FramedData这是一个彻底管理方法的解决方法,这代表你不用做一切事儿,只是坐下来等候看法。架构数据信息从公司读取数据,并将其转换为行得通的看法和管理决策。她们在云上训炼、提升和存储产品的弱电解质实体模型,并根据API出示预测分析,清除系统架构花销。她们出示了汽车仪表板和场景分析工具,对你说什么企业杆杠是安全驾驶你关注的指标值。
6.KaggleKaggle是世界最大的计算机科学小区。企业和科学研究工作人员贴到她们的数据信息,来源于世界各国的统计人员和大数据挖掘者争相制做最好是的实体模型。Kaggle是计算机科学比赛的服务平台。它协助您处理难点,征募强劲的团体,并扩张您的计算机科学优秀人才的能量。
7.Weka,WEKA是一个比较复杂的大数据挖掘专用工具。它向您展现了uci数据集、群集、预测分析模型、数据可视化等层面的各种各样关联。您能够 运用多种多样分类器来深入了解数据信息。
8.RattleRattle代表R分析工具。它给出的数据的统计分析和数据可视化归纳,将数据转换为能够 轻轻松松模型的表格,从数据信息中搭建无监管实体模型和监管实体模型,以图型方法展现实体模型的特性,并对新uci数据集开展得分。它是一个应用Gnome图形化在统计分析語言R撰写的完全免费的开源系统大数据挖掘常用工具。它运作在GNU/Linux,MacintoshOSX和MS/Windows下。
9.KNIMEKonstanz信息内容数据采集器是一个客户友善、可了解、全方位的开源系统数据集成、解决、剖析和探索平台。它有一个人机交互界面,协助客户便捷地联接连接点开展数据处理方法。KNIME还根据模块化设计的数据信息生产流水线定义集成化了深度学习和大数据挖掘的各种各样部件,并造成了商务智能和会计数据统计分析的留意。
10.Python做为一种完全免费且对外开放源码的語言,Python一般 与R开展较为,以使用方便。与R不一样的是,Python的学习通常很短,因而变成传奇私服。很多客户发觉,她们能够 刚开始搭建uci数据集,并在十多分钟内进行极为繁杂的感染力剖析。要是您了解自变量、基本数据类型、涵数、标准和循环系统等基础程序编写定义,最普遍的业务流程用例大数据可视化就非常简单。
11.Orange是一个以Python語言撰写的根据部件的大数据挖掘和深度学习手机软件模块。它是一个开放源码的大数据可视化和剖析的初学者和权威专家。大数据挖掘能够 根据可视化编程或Python脚本制作开展。它还包括了数据统计分析、不一样的数据可视化、从散点图、条形图、树、到树图、互联网和热点图的特点。
12.SASDataMining应用SASDataMining商业软件发觉uci数据集方式。其说明性和预测性模型出示了更强的了解数据信息的看法。她们出示了一个便于应用的GUI。她们有着自动化技术的数据处理方法专用工具,群集到最后能够 寻找恰当管理决策的最好結果。做为一个商业软件,它还包含可升級解决、自动化技术、加强优化算法、模型、大数据可视化和勘查等优秀专用工具。
13.ApacheMahoutApacheMahout是Apache手机软件慈善基金会(ApacheSoftwareFoundation)的一个新项目,用以转化成关键集中化在合作过虑、聚类算法和归类行业的分布式系统或别的可伸缩式深度学习优化算法的完全免费保持。ApacheMahout关键适用三种用例:提议发掘采用客户个人行为,并试着搜索客户将会喜爱的新项目。群集必须文本文档,并将他们排序为部分有关的文本文档。归类从目前的归类文本文档中学习培训到特殊类型的文档是什么模样,并可以将未标识的文本文档分派给(期待)恰当的类型。
14.PSPPPSPP是对取样数据信息开展数据分析的程序流程。它有一个人机交互界面和传统式的命令行界面。它用C语言撰写,应用GNU科学研究图书管的数学课例程,并绘图UTILS来转化成数据图表。它是特有程序流程SPSS(来源于IBM)的完全免费代替品,能够 信心地预测分析接下去会产生哪些,便于您能够 作出更聪明的管理决策,解决困难并改善結果。
15.jHepWorkjHepWork是一个完全免费的对外开放源码数据统计分析架构,它是以便应用对外开放源码程序包和可了解的操作界面建立一个数据统计分析自然环境,并建立一个与商业服务程序流程相市场竞争的专用工具。JHepWork显示信息uci数据集的互动式2D和3d图纸,便于尽快剖析。Java中保持了大数字科学研究库和数学函数。jHepWork根据高級计算机语言Jython,但Java编号也可用以启用jHepWork标值库和图形库。
16.RprogrammingLanguage,为何R是这一名册上完全免费大数据挖掘专用工具的超级明星,它是完全免费的、开源系统的,而且非常容易为这些沒有程序编写工作经验的人选择。事实上,有不计其数的库能够 集成化到R环境中,使其变成一个强劲的大数据挖掘自然环境。它是一个免费的软件计算机语言和手机软件自然环境,用以统计分析测算和图型。在数据信息开采者中普遍应用R语言开展统计软件和数据统计分析。近些年,便捷性和扩展性进一步提高了R的名气。
17.PentahoPentaho为数据集成,业务流程剖析和互联网大数据出示了一个全方位的服务平台。拥有这一商业服务专用工具,你能轻轻松松地结合任何来源的数据信息。深入了解您的业务流程数据信息,为将来作出更精确的信息内容驱动器管理决策。
18.TanagraTANAGRA是一个用以学术研究和科学研究目地的大数据挖掘手机软件。有探索性数据统计分析,统计学习,深度学习和数据库查询行业的专用工具。Tanagra包括一些监督学习,但也包含别的案例,如聚类算法,因子分析,主要参数和非参数统计,关联规则,数据预处理和搭建优化算法。
19.NLTK自然语言理解常用工具,是一套用以Python語言的标记和统计分析自然语言理解解决(NLP)的库和程序流程。它出示了一个語言解决专用工具库,包含大数据挖掘,深度学习,数据信息报费,情感分析和别的各种各样語言解决每日任务。搭建python程序流程来解决人们語言数据信息








@Copyrights 2016-2026 杭州玳数科技有限公司浙ICP备15044486号-1浙公网安备33011002011932号

